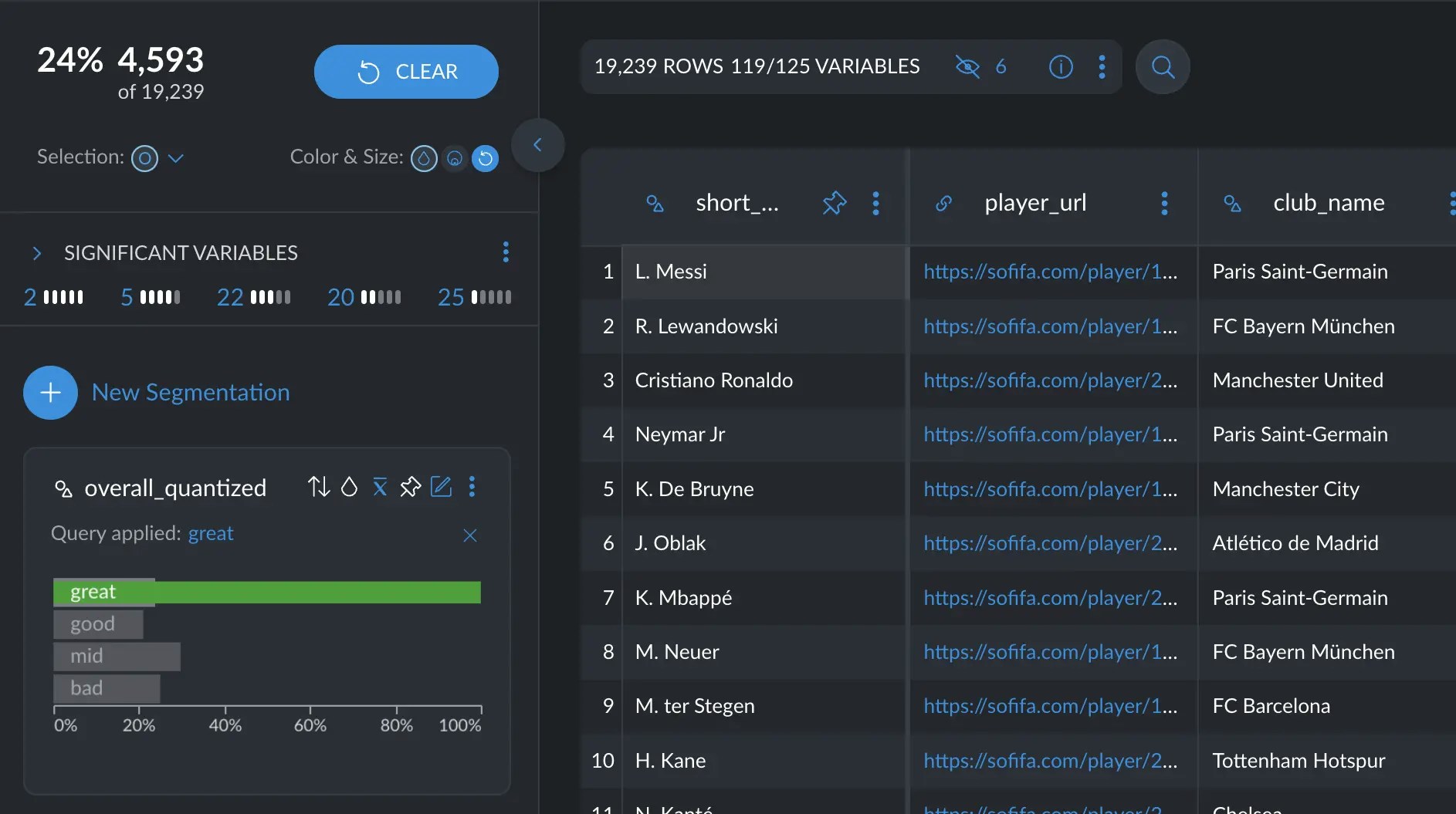
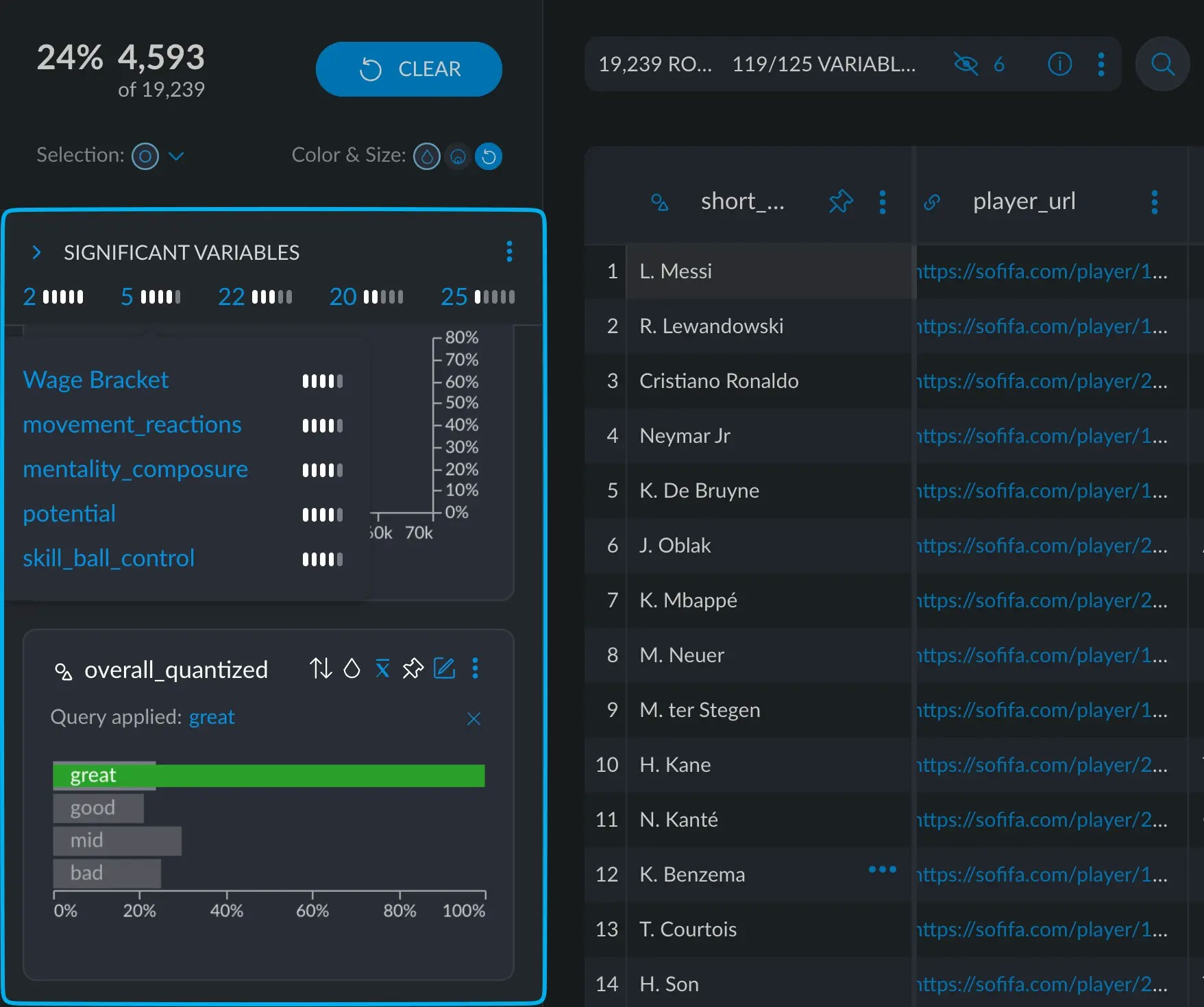
Clicking the number will reveal all the variables that belong to this group of significance. In the example, we see all the variables with a score of 4 out of 5.
How is the score calculated?

Manually computing an example
Context
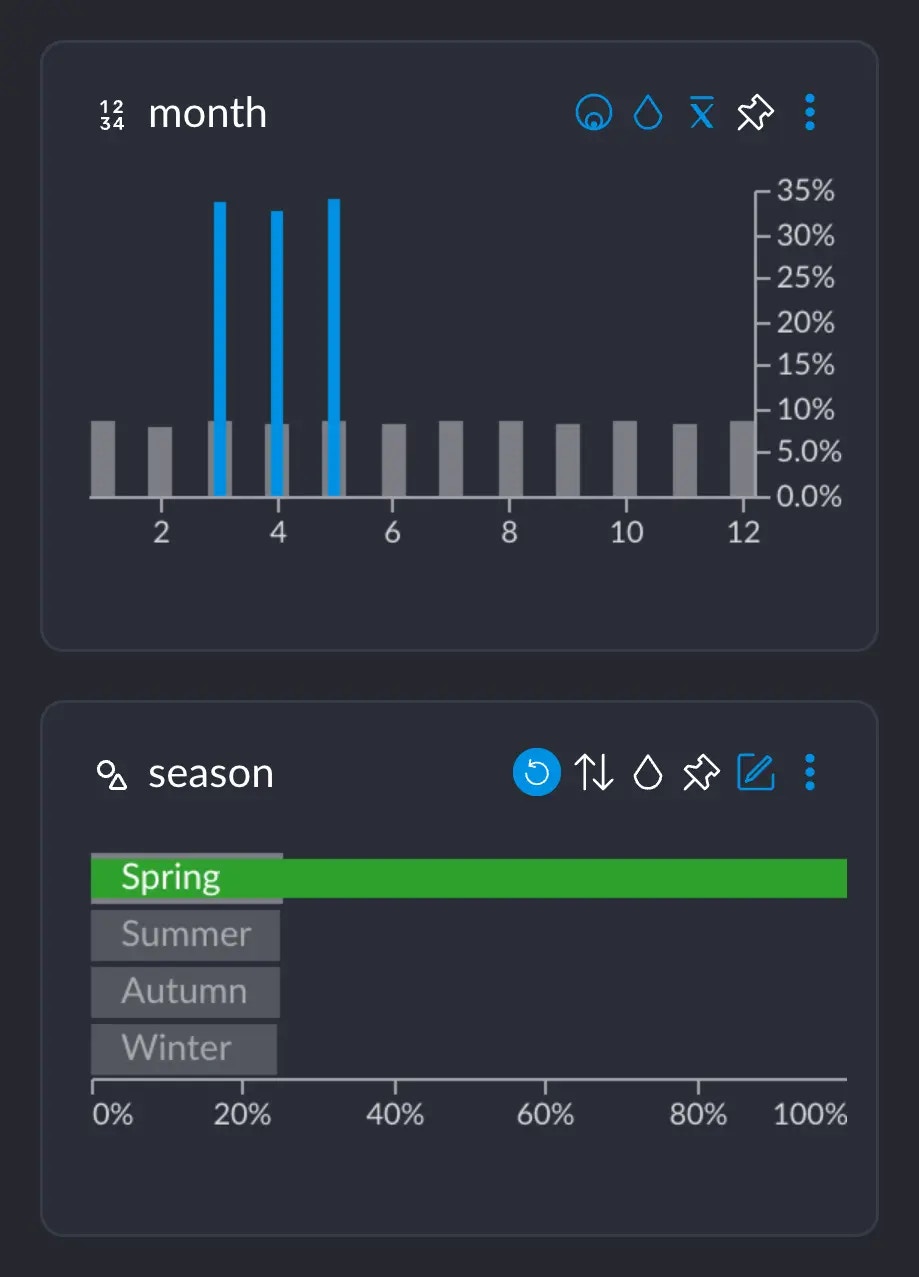
Assume we are on a dataset where, among other things, we have a columnmonth which has the numbers 1 – 12 for each month,
and a column season which has the values “Summer”, “Autumn”, “Winter”, “Spring”.
We all know that in the northern hemisphere, Spring happens in March, April and May, approximately. If we select the category “Spring”, we can see
that the months 3, 4 and 5 show up these blue spikes, whereas the rest of the months do not.
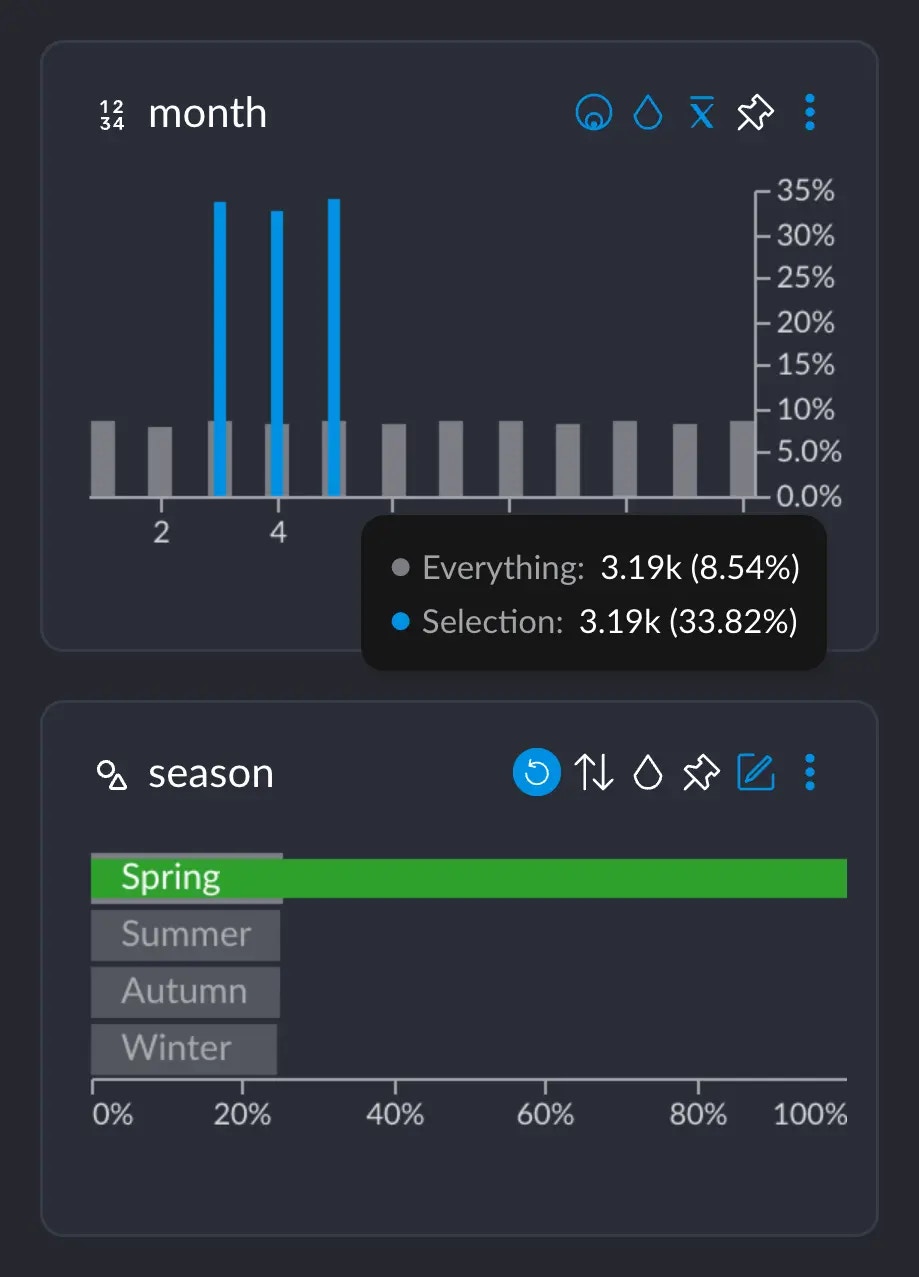
- 3.19K represents the number of rows that have this particular value from this particular column (in this case, the value 5 for column
month). Or, basically, the grey-ish bar behind the blue one. - This 3.19K amounts to an ~8.5% of the whole dataset, which has ~37.3K rows.
- Importantly, these 3.19K rows correspond to ~33% of all the 9442 rows we selected when clicking on “Spring”. This makes sense: spring spans across 3 months, so May alone has about a third of all the days that comprise the whole Spring.
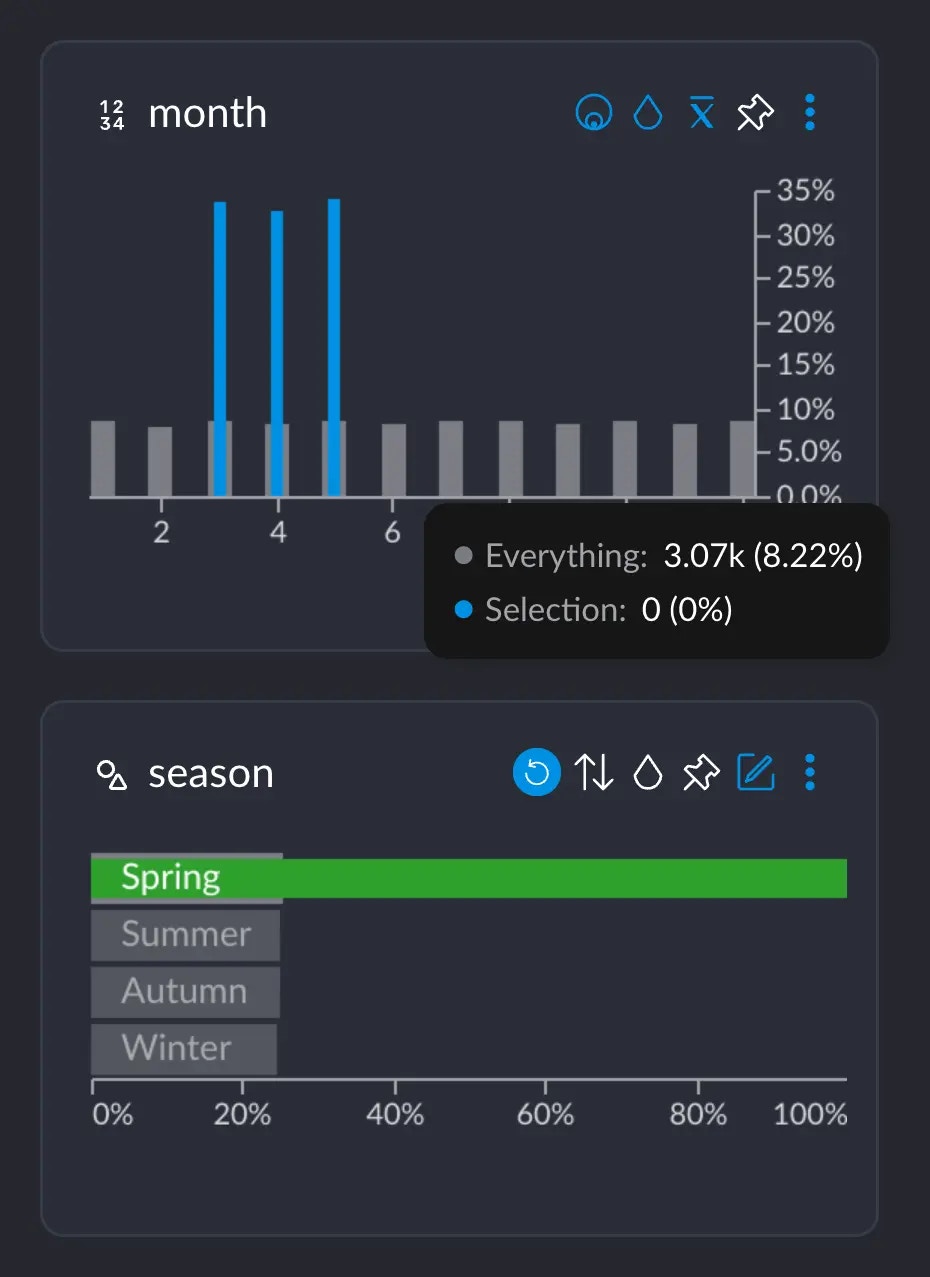
month AND the value “Spring” in season.
Computing
The way we calculate how different the distributions between month and season are would involve going over each of these tooltips, subtracting the two percentage values, getting the absolute value, adding them all up and finally dividing by two. The full operation would look like this.- We add up all the absolute value of the differences:
- Finally, we divide the whole result by 2:
month in the significant variables section:
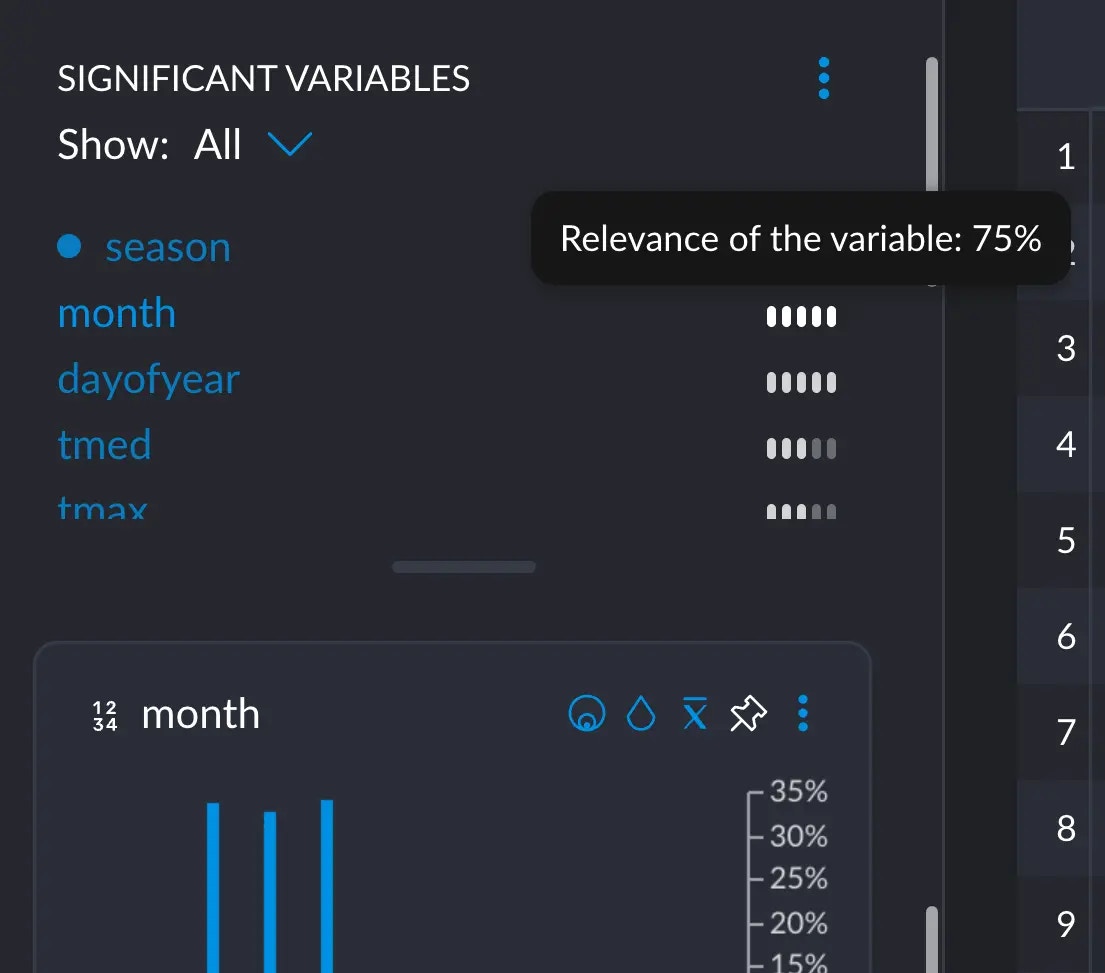
We are not proving and demonstrating all the math behind this, since this
flies a bit out of the scope for this short explainer. Check the
references if
you really want to dig into the topic.