Custom Query Selection
Cross filters also allow you to make arbitrary selections, with a specific, but simple syntax.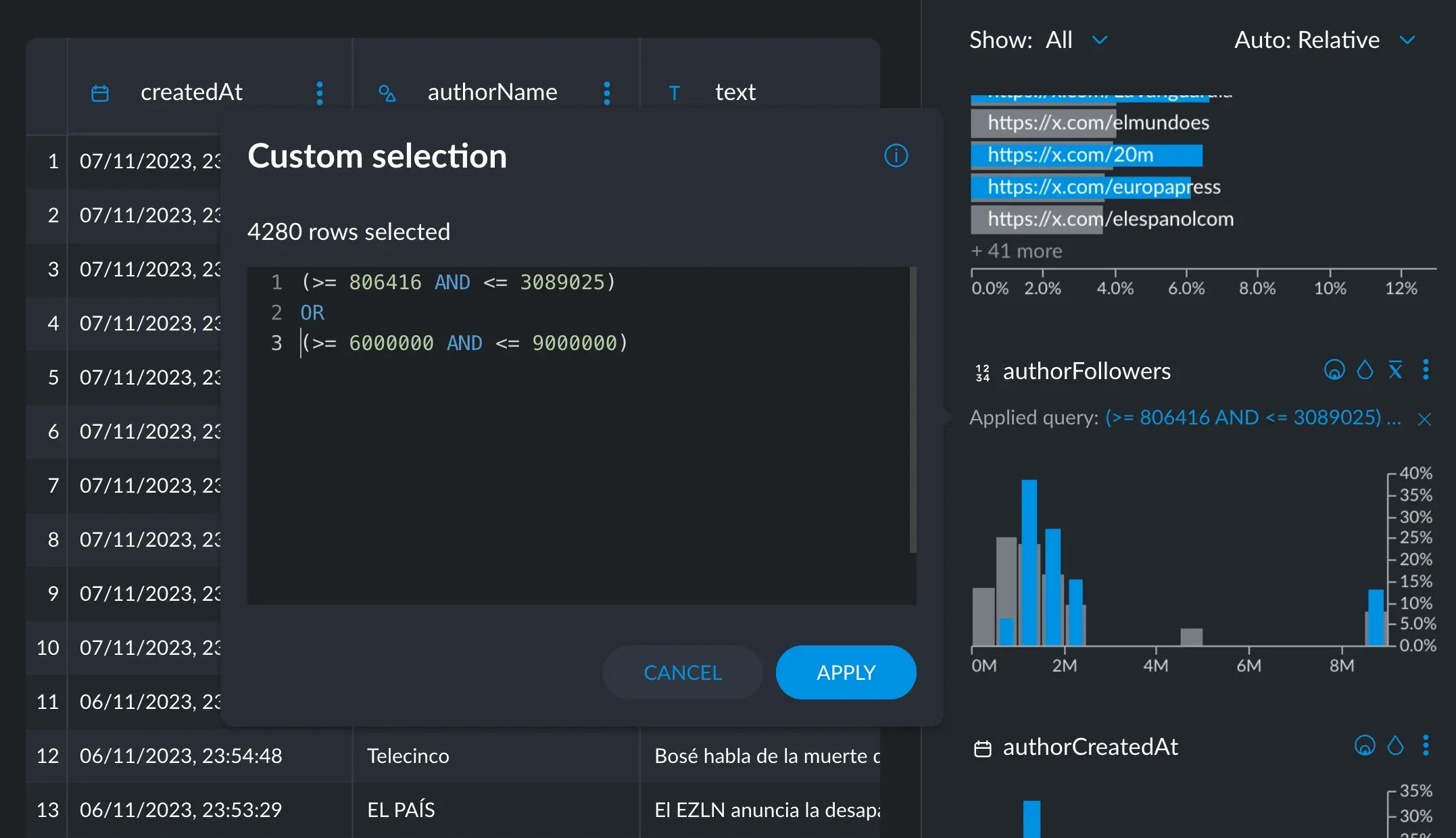
- logical:
AND, OR, NOT - numerical:
<, >, <=, >= - text:
REGEX, SUBSTR, FUZZY - frequency selection:
TOP, FREQ - sorting methods (to be used with
TOP):BACKGROUND, FOREGROUND, UPLIFT, TFIDF, ORDINAL - null values:
NULL - statistics:
MIN, MAX, MEAN, P25, MEDIAN, P75
- All column types accept the logical operators to build complex queries using other operators, as well as the
NULLoperator, which exclusively returns null rows.
Logical operators
Logical operators can concatenate simpler expressions to build more complex ones. This selects all rows that have aage value greater than 10 and less than 55:
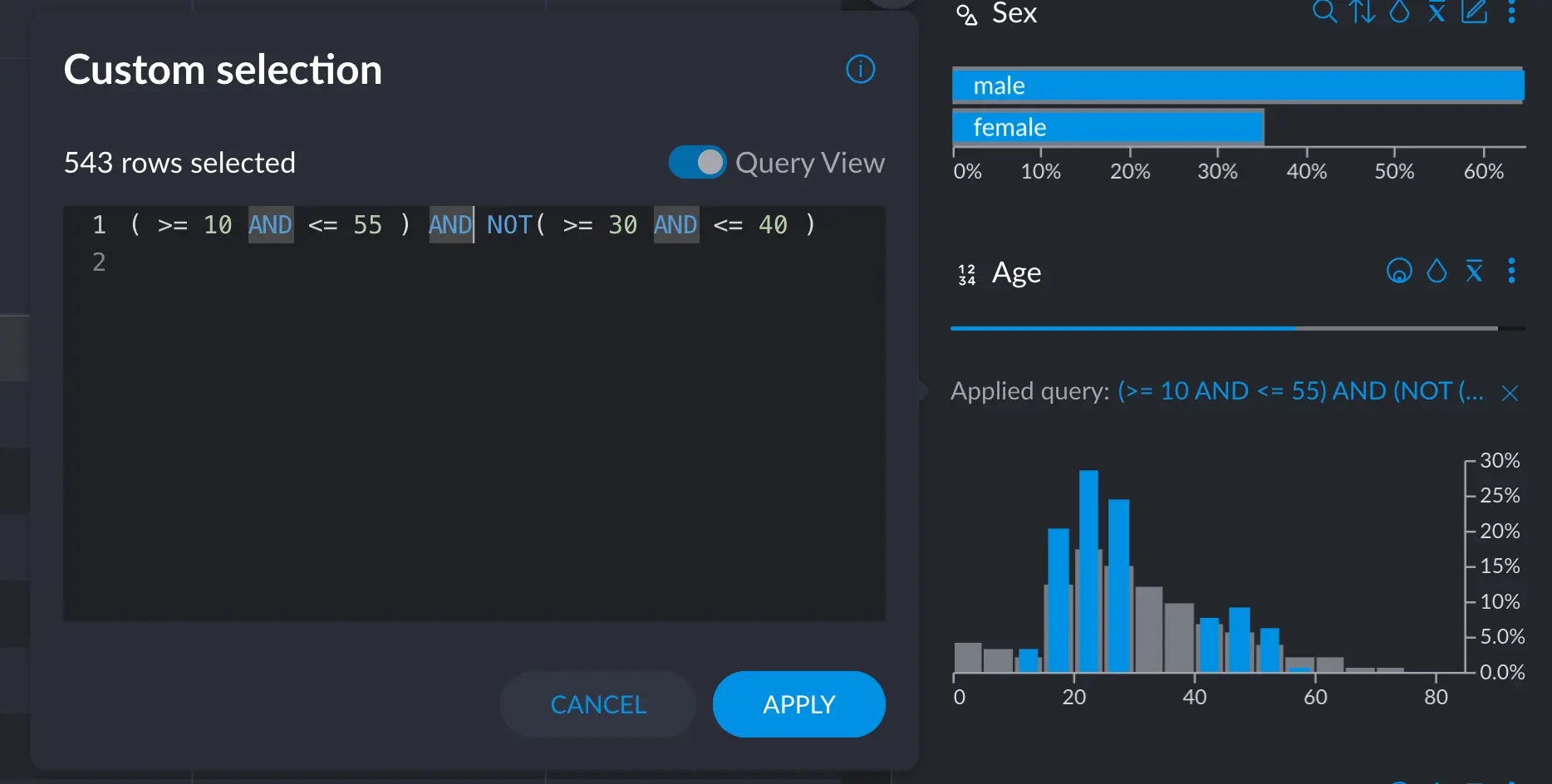
Categorical & Text
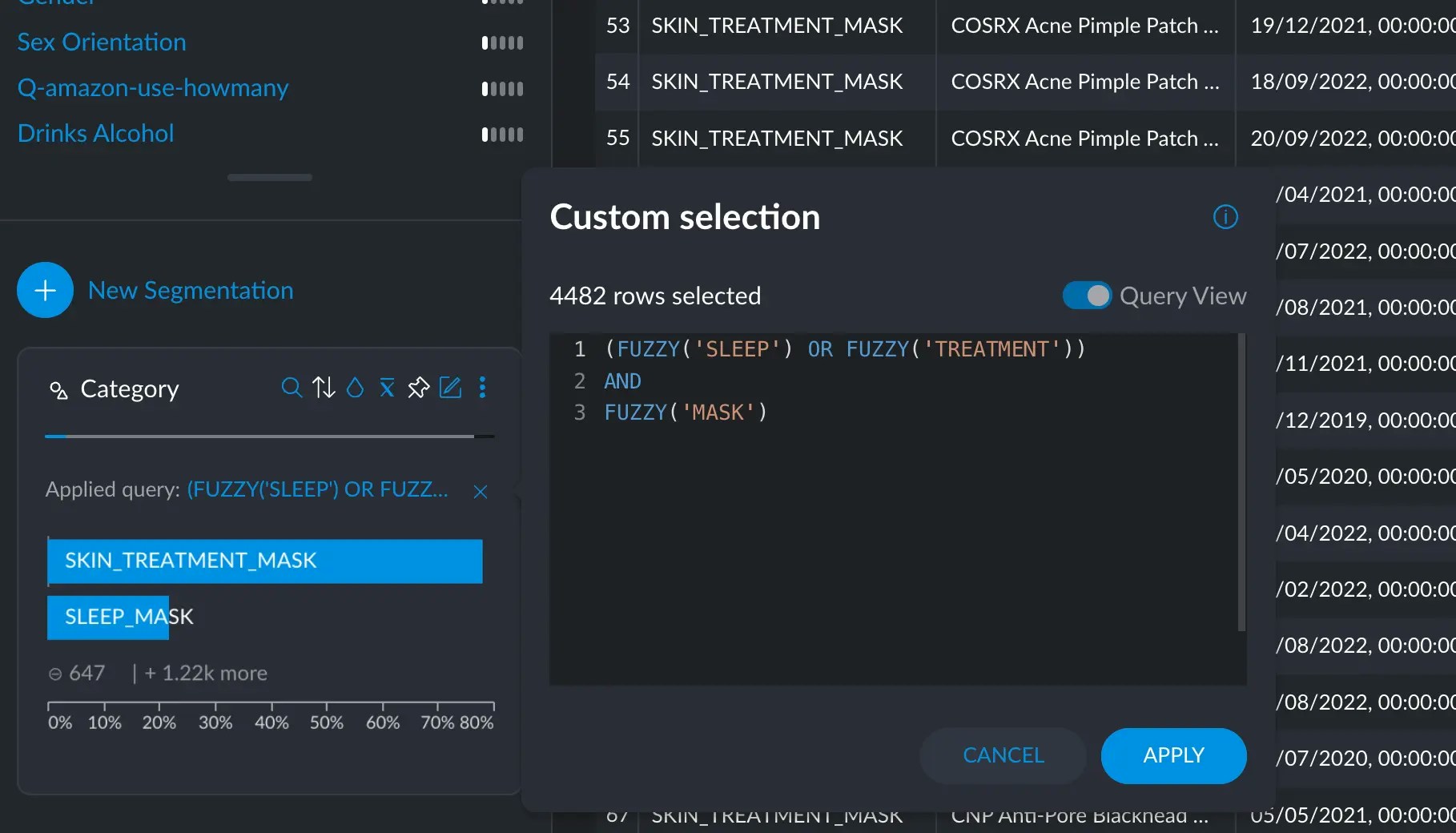
In categorical or text columns you can search for specific words (tokens) or categories. You can combine searches using boolean logic (i.e. string together multiple conditions using the AND/OR keywords). Categorical and Text variables accept theTOP, FREQ, FUZZY, SUBSTR and REGEX operators. They work similarly since
both are based on text: categories are just very short expressions, whereas text
tends to present a longer format.
- On any text-based variable, you can simply ask for
ball, which will return all rows that contain the wordballby itself. FUZZY(ball)will return all rows that contain the wordball, whetherballis part of other words or appears by itself.FUZZYis case insensitive and normalizes all input (a.k.a ASCII folding) before searching.
SUBSTR(ball)will return only rows that containballas part of a word, but not by itself.REGEX()will accept a regular expression string to match more complex patterns.
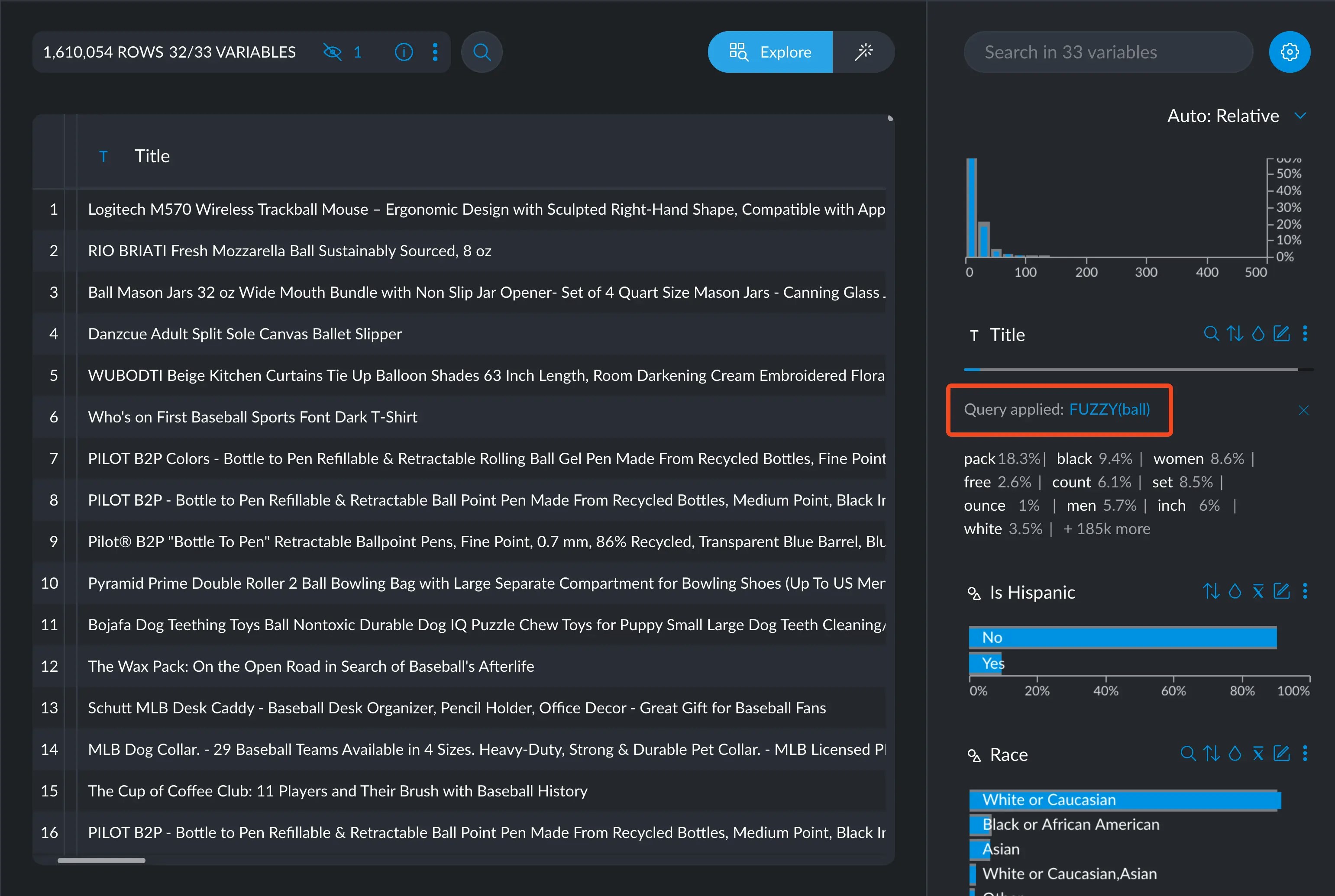
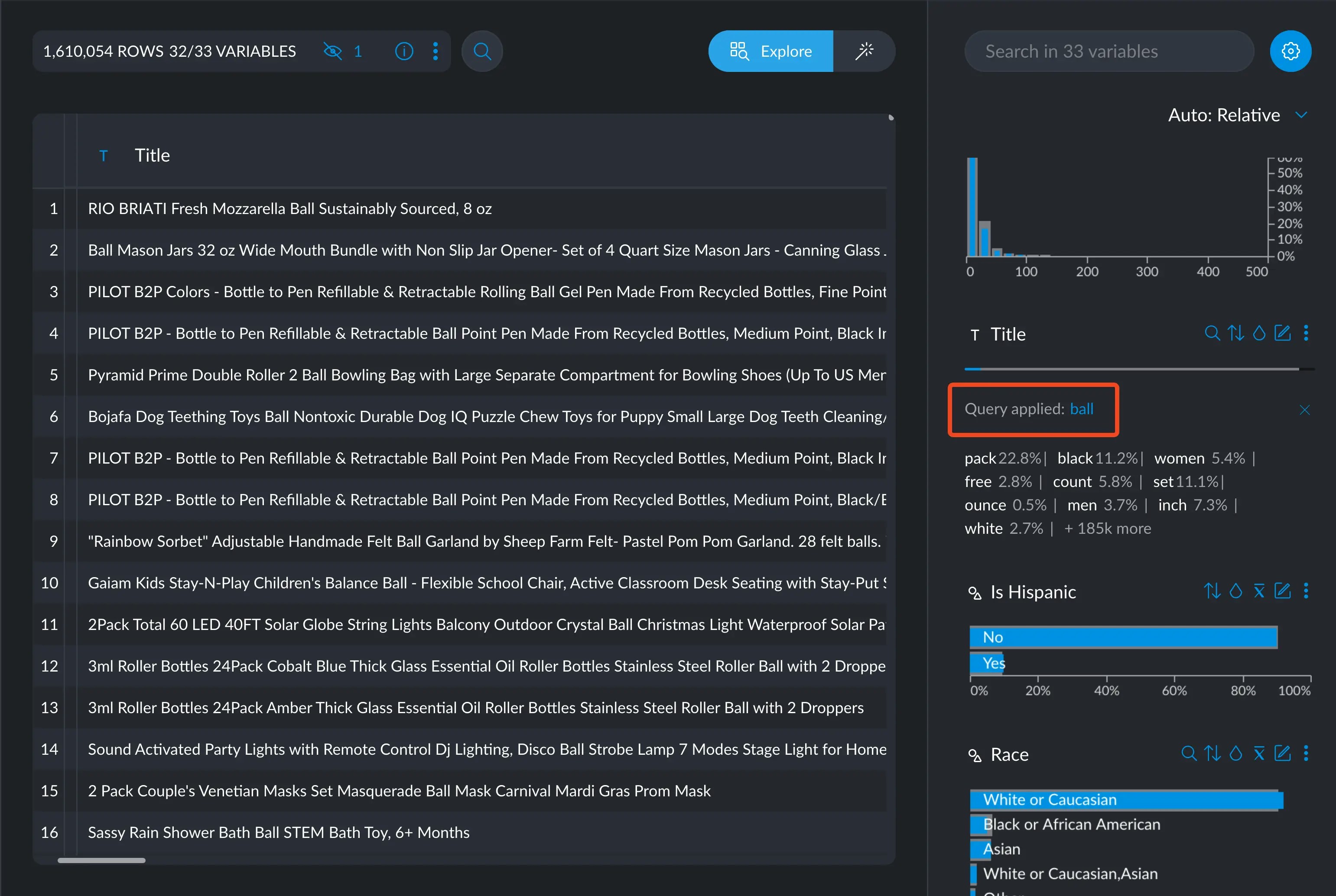
Selecting FUZZY(ball) yields more results than just ball
FREQselects those terms whose frequency is greater or equal thann:FREQ(10000)selects those values whose frequency is greater or equal to 10K.TOPselects the topnterms in terms of frequency:TOP(10)selects the top 10.- we can, however, modify
TOP’s behavior by sayingTOP(10, FOREGROUND), which would select the top 10 out of the current selection we have made. TOP(10, UPLIFT)selects the top 10 after sorting them by how different the frequency is between the selection and the whole dataset. These operators are the same as the ones mentioned in the sorting section.
- we can, however, modify
Keep in mind that the sorting methods will not visually sort the elements in
the cross filter, but they will just return the relevant elements once they
are filtered and sorted. To sort the elements visually, you can head to the
sorting section.
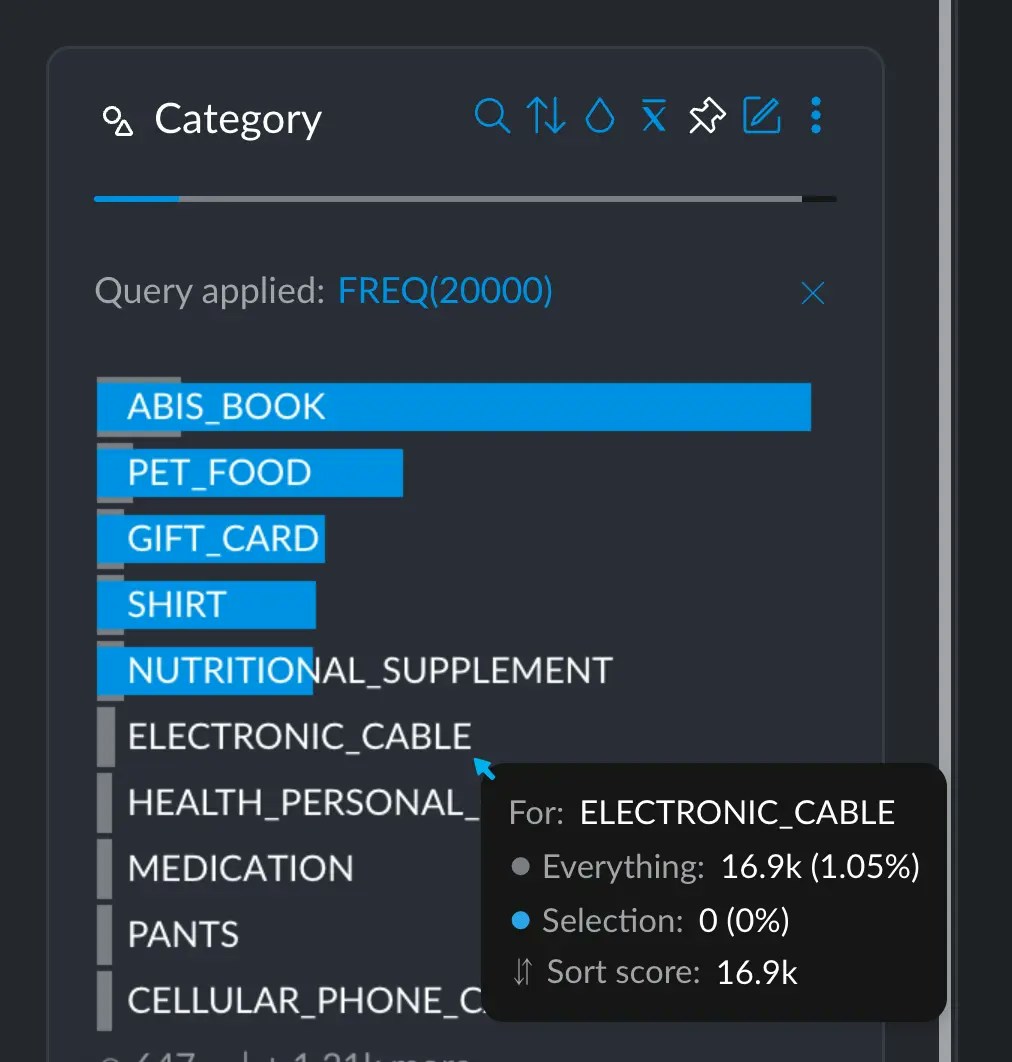
Since ELECTRONIC_CABLE has ~17K occurrencies, it was left out of the greater than 20K selection.
Text or category notation examples
Text or category notation examples
Select rows where the on the other hand, rows that include “engineering”, maybe among other terms:or where the or filter the top four most frequent categories in the select all rows that have over 20K occurrencies:
department column exactly contains “engineering”:text column exactly matches “he” and “she”:department column:Numerical & Dates
Numerical and Date columns behave similarly, since, internally, they are just storing numbers. This section explains valid syntax and examples for each type.Numerical
Numerical variables will naturally accept the numerical operators, as well as the statistical operators.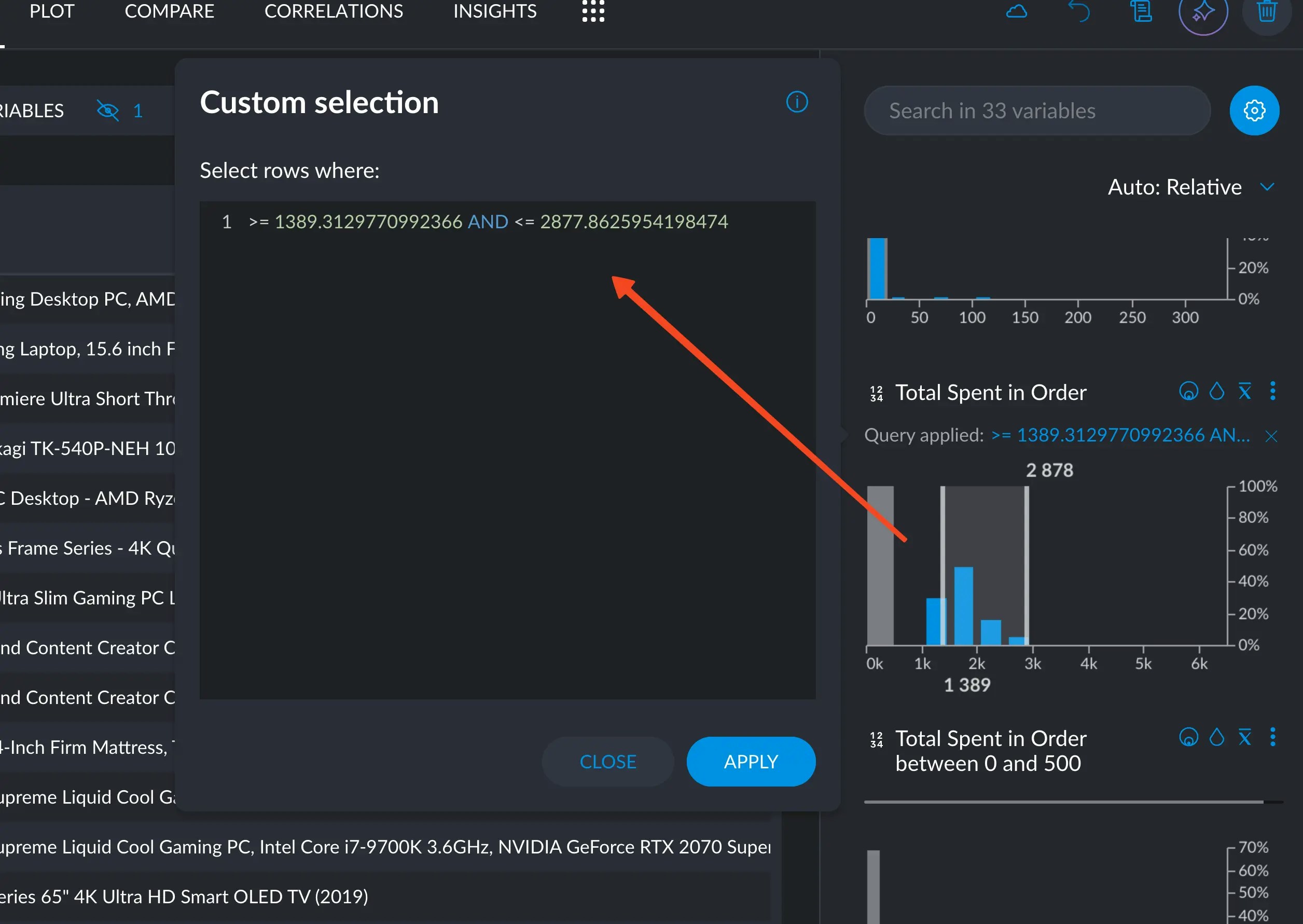
Simply selecting a range in the little plot will create a query string with the greater/less than and AND operators.
- MIN: selects all rows that have the same value as the minimum value found
- MAX: selects all rows that have the same value as the maximum value found
- MEDIAN: selects all rows that have the same value as the median
- P25: selects all rows that have the same value as the first quartile
- P75: selects all rows that have the same value as the third quartile
>= P25 AND <= P75, which returns all rows that are both
greater or equal than the P25 and less or equal than the P75. This effectively returns the the interquartile range.
In numeric columns, numbers can also be specified using scientific notation. The following two numbers are both valid and represent the same number: 145000 and 1.45e5.
Queries in numeric columns support =, >, >=, < and operators.
Numerical Notation Examples
Numerical Notation Examples
To select rows whose age field falls into the range 10 to 55:To match a specific number:The = operator is implicit in the above query, so the following query produces the same result:Selecting everything BUT a specific number:Include ages from 10 up to but not including 55 (exclusive smaller/greater than):Using scientific notation:Using a computed statistic, anything over the 25th percentile:Or anything under the 75th percentile:Retrieving the interquartile range:Combining both constants and computed statistics:
Dates
Dates behave in much the same way as numbers. They are specified in the ISO format 8061 standard, where the date part is required and the time part optional. I.e. both the following dates are valid: 2020-02-23 and 2020-02-23T14:30:00. In the first example, only year, month and date are specified, while the second includes the time also (hours, minutes and seconds) We can say things like>= 2018-06-05T11:33:48.554Z AND <= 2021-06-26T05:56:18.172Z, which means anything after June 5th, 2018 at 11:33:48 and before June 26th, 2021 at 05:56:18, effectively
returning dates within that time interval. Same as with numbers, simply creating a range in the cross filter will generate this query for you to adjust, in case more precision was needed.
Here are some examples of valid date notation:
To select all rows whose “date” field falls into the year 2019:
Date notation examples
Date notation examples